FREQUENTLY ASKED QUESTIONS
Operational Frameworks for AI Evaluation Beyond Benchmark Scores


When it comes to AI model evaluation, enterprise technology leaders are fast discovering that benchmark scores alone are insufficient in predicting real-world reliability.
AI evaluation frameworks include the tools, metrics, and workflows used to test, control, and validate an AI model's performance. However, many models that perform well in standard benchmark environments still fail in production. In fact, a recent MIT study revealed that 95% of generative AI pilots at companies are failing.
While high benchmark scores initially give organizations a strong sense of confidence, production reveals a whole different reality. Once deployed, models struggle to interpret the unpredictable user behavior, nuanced context, and edge cases that were not present in controlled testing environments.
Recognizing that high benchmark scores don’t guarantee real-world success is driving a major shift in how AI models are being evaluated and monitored in 2026.
"One of the biggest misconceptions around AI deployment is that benchmark performance translates directly into production reliability," says Amanda McLean, VP of Sales & Customer Enablement at ClinCapture. "In regulated environments like clinical research and healthcare technology, operational consistency and human oversight matter far more than leaderboard scores alone."
Modern AI evaluation needs to extend beyond benchmark testing to include production monitoring, human review systems, and operational validation workflows.
Why AI Benchmarking Fails to Measure Real-World AI Reliability
Fundamentally, AI benchmarking tests fail because they are performed in static environments, with fixed data sets. However, real-world production workflows are always dynamic. An LLM may pass a benchmark test in 2024, but fail the same evaluation in 2026 due to distribution drift (changes in consumer trends, macroeconomic shifts and new slang), showing just how quickly data becomes outdated.
AI validation frameworks use clean, structured data, whereas in real-life scenarios, humans make spelling mistakes and input messy, ambiguous queries. If an LLM has only ever been exposed to clear, straightforward inputs, it is likely to struggle to understand real user intent.
Additionally, LLM evaluations use a finite number of test cases, which does not mirror how LLMs are used in practice. While benchmark AI tools may include 10,000 cases, real users generate billions of queries, leaving room for 1000s of cases the model is not equipped to handle.
"Benchmark performance does not necessarily predict how that performance translates into reliability once the model is put into production," says Edward Tian, Founder and CEO of GPTZero. "Many AI systems fail in production because of edge cases, ambiguous inputs, interruptions in workflow, and distribution shifts, none of which are represented in leaderboard performance evaluations."
Kenny MacAulay, CEO at Acting Office, has witnessed this first hand:
"One of the biggest operational lessons companies learn after deploying AI is that benchmark performance rarely reflects real production reliability. We have seen that hallucinations and context misunderstandings are still among the most common issues that escape automated evaluation systems, especially in customer-facing workflows where queries are unpredictable. Automated testing can catch formatting and logic problems, but edge cases, ambiguity, and tone-related failures still require regular human review.”
He further argues that “the companies handling AI successfully usually build layered validation systems, rather than relying entirely on the model itself. In sensitive industries like healthcare, finance, and legal services, continuous human oversight remains essential because even small inaccuracies can create serious operational or compliance risks."
According to MacAulay, the most important element for reliability is workflow design. Production-ready AI requires setting up quality data retrieval, structured prompts, and clear human guardrails as early as possible.
Essential AI Evaluation Metrics for Operational Success
For real-world applications to be successful, AI auditing needs to move beyond accuracy to focus on the metrics companies actually use in production.
“In practice, the most important evaluation metrics are consistency, factual accuracy, response relevance, escalation rate, and how often human correction is required over time,” says MacAulay (Acting Office).
Ritwick Dey, Co-founder of Panto AI argues that “AI reliability in production should be measured by business-aligned Service Level Objectives (SLOs), continuous monitoring, and targeted human review”, rather than solely through benchmark scores.
"The most useful question is not whether the answer is right, but rather what happens if the answer is wrong,'" says Nicolas More, Founder at Mentiohunt. "Teams should track failure severity, user correction rate, escalation rate, and whether bad outputs are recoverable."
AI evaluation metrics that reflect this reality include:
Moe Rosenfeld, CIO of eCopier Solutions adds that “the metric that matters most in production is the cost of a wrong answer in context. In the document environments we manage for healthcare and legal clients, a hallucinated output isn't an inconvenience, it's a compliance event. So the evaluation framework has to start there: what does failure actually cost, and is the human review layer upstream of that consequence or downstream of it.”
Today, real production success is defined by how quickly and accurately errors can be rectified and operations restored to normal. Shifting AI model evaluation frameworks to focus on the real world severity and business risks allows organizations to build the right contingency plans and safety nets during AI integration.
Why Human-in-the-Loop AI Validation Is Still Critical
While leaders once envisioned automated operations, enterprise AI reliability increasingly depends on structured human-in-the-loop AI review systems. Instead of removing humans, hybrid workflows require humans at the centre.
Successful companies are incorporating the following systems into their workflow:
- Continuous AI Model Validation: Consistent human monitoring of AI outputs that checks for inconsistencies, errors, hallucinations, data drift, nuanced context failures and edge cases.
- Human Review Queues: Dedicated queues where flagged AI outputs are sent for human auditing.
- Escalation Systems: A system that detects when an AI model is struggling with a query and escalates that task to a human expert.
- Sampled Audits: Running weekly audits on between 2% and 5% of successful automated AI outputs to catch errors that may have slipped through.
- Operational Oversight: Monitoring AI performance, adjusting guardrails and taking accountability for mistakes in the same way managers would for human employees.
This shift has turned human-in-the-loop validation from a temporary solution into an essential system layer. As Jared Grubka, co-founder and COO of Faliam, explains: “Exception funnels route edge cases to human operators. Errors often escape automated systems when context is nuanced or data is sparse. Healthcare and fintech industries demand continuous human validation due to regulatory needs.”
In this way, organizations need to balance automation with strict human oversight. Low risk, high-confidence tasks can be fully automated, while high risk potential edge cases should always be escalated to prevent expensive operational failures.

This hybrid approach is especially important when organizations face nuanced context failures, such as errors that look correct on the surface, but are contextually wrong.
Quin Thames, Head of Nutrition at SnapCalorie, an AI-powered app that tracks nutrition via photos, explains how context failures are avoided:
“At SnapCalorie, the most critical metric is real-world accuracy. We validate our AI's nutrition estimates against human nutritionists and live audits to ensure consistent precision. Human review plays a key role, especially for edge cases like complex meals or ambiguous photos, which automated systems struggle to evaluate accurately. Layering human oversight with AI for consistent quality, even the most advanced models need feedback loops to improve over time.”
Thames’ experience highlights that automated testing alone cannot handle the unpredictability of real-world data. However, with live audits and expert nutritionist validation, human corrections can create feedback loops that train the model over time.
This need for continuous machine learning model validation becomes even more crucial in highly regulated, compliance-sensitive environments like healthcare workflows. In these industries, even minor AI hallucinations can result in major legal liabilities or pose serious risks to patients.
As McLean (ClinCapture) points out, “Human review is especially important when workflows involve compliance requirements, patient data handling, or downstream operational decisions. The most effective deployments are typically the ones where AI supports trained human teams instead of attempting to eliminate oversight entirely.”
As validation workloads grow, many organizations realize that running review queues, audits, exception handling, and validation workflows becomes an operational discipline of its own. Rather than building dedicated validation teams internally, many companies choose to partner with specialized AI validation providers that manage these workflows at scale.
By owning the day-to-day operations of exception queues, data validation partners provide the human review layer needed to keep production workflows safe without adding management, training or supervision overhead to internal teams.
The Operational Problems Automated AI Evaluation Still Misses
While AI evaluation tools excel at catching formatting issues, spelling mistakes and broken code, nuanced, context-specific problems are frequently missed.
Rosenfeld (eCopier Solutions), explains that “Automated systems check for correctness in the abstract. They're not good at catching answers that are right in general and wrong specifically.”
The most common operation failures in enterprise AI include:
- AI Hallucinations: When models confidently fabricate information that is not grounded in reality or truth.
- Plausible Lies: False AI outputs that sound professional and well-articulated, making it difficult for automated tools to flag them.
- Context Failures: When a response is factually correct, but has been used in the wrong context.
- Domain-Specific Constraints: Missing or violating the rules of a specific industry or client by changing regional laws or specialized technical jargon.
- Workflow Regressions: When an AI model update or prompt change breaks a working feature, causing a step in a business process to fail.
- Edge Cases: Unusual or complicated cases caused by shifts in data or unpredictable user behaviour that AI has not been trained to handle.
As David Forino, CTO of Quanted points out:
“The errors we see now aren't compilation errors, they're bugs around edge cases. The question I ask on every task is whether it's well defined with proper context and rules, or whether it's open ended. If the task is well scoped, current AI is incredibly good at following instructions. If it isn't, no automated eval [evaluation] will catch what goes wrong, because you haven't defined what 'right' looks like in the first place.”
Automated tools also lack the human domain expertise required to spot subtle domain errors. Raymond Roberts, AI Systems Architect at Esko, explains that “the hardest errors are often subtle domain errors. This is why the biggest value often comes from combining newer LLM and vision-language capabilities with specialized systems and domain expertise that have already been proven in production.”
To truly evaluate LLMs for AI reliability, companies have learnt the hard way not to rely on formulas. What actually matters is how the AI handles highly specific edge cases when things get messy.
AI Validation Frameworks Need More Than Benchmark Scores
To build more reliable AI, the operational systems surrounding the model need to be airtight. The majority of the time, the issue is not with the model itself, but rather how it has been trained, and the contingencies that have been set up for when things fail.
“The surprise is that reliability is an operations problem, not only a model problem,” says More (Mentiohunt). “You need routing rules, review queues, fallback paths, and clear ownership when AI is uncertain.”
Roberts (Esko) adds that “what differentiates experiments from enterprise-grade AI is the harness around the model.” An enterprise-grade AI evaluation framework should include the following ‘safety harness’ of deterministic tools:
- Schema Validation & Execution Graphs: Strict code limits that control exactly what the model can output and what actions it can take.
- Traceability & Audit Trails: Recording every step the AI took to reach an answer, so that the process is easy to review.
- Operational Monitoring & Observability: Treating the AI system like a factory floor, with clear AI monitoring tools tracking system health.
- Operational Ownership: Assigning real human managers to take responsibility for the AI's daily outputs.
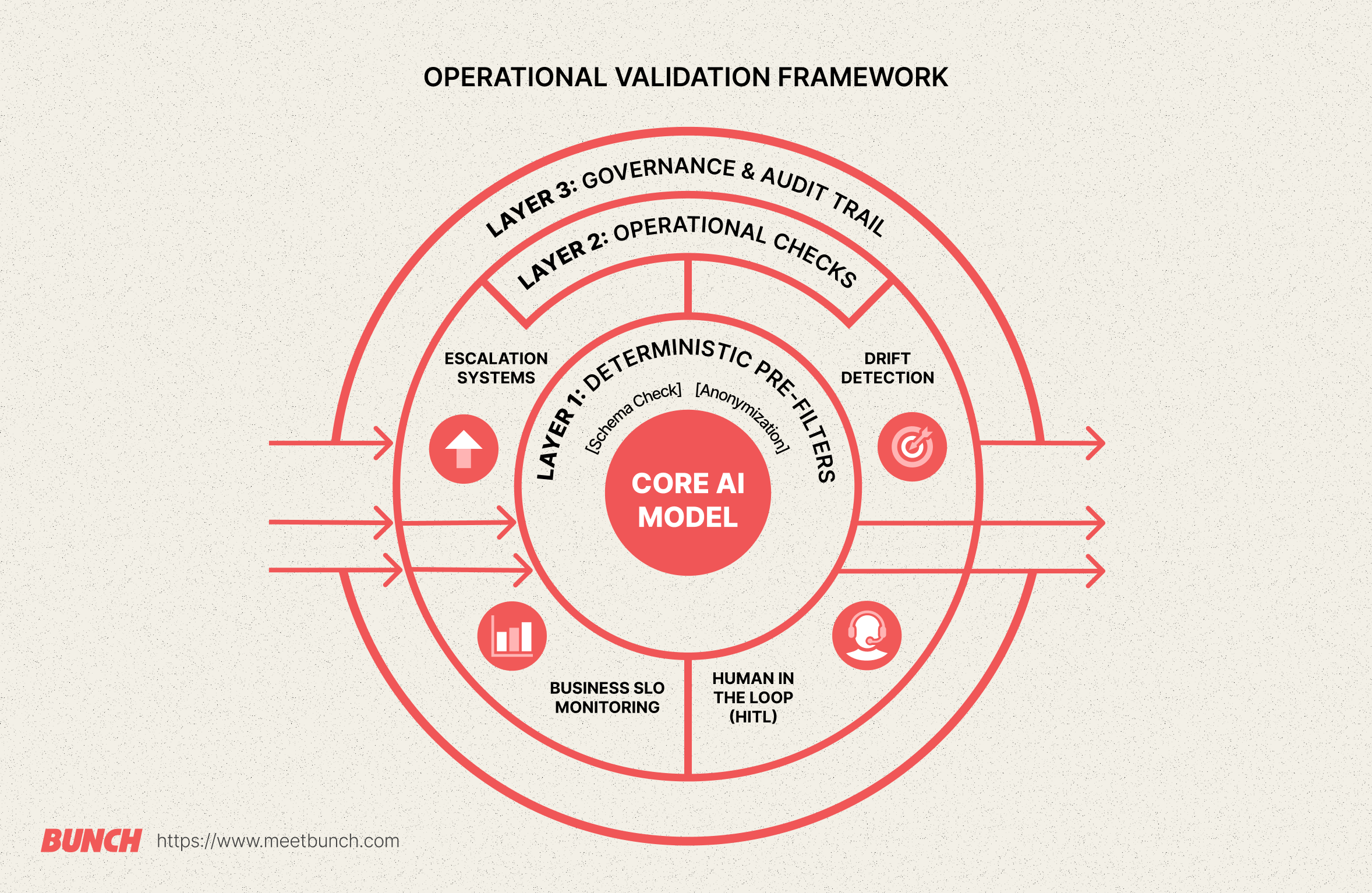
As Dey (Panto AI), notes:
“Production inputs diverge faster than expected; tooling for drift detection and fast rollback beats frequent full retrains. Teams underinvest in escalation playbooks and provenance, which lengthens incidents.” When things go wrong, systems need clear escalation guidelines, remediation workflows, and rollback systems. Because you cannot fix a production error by retraining the entire model.
Ultimately, true AI model validation and AI governance comes down to structural planning. Proper workflow design, clear escalation paths, high retrieval quality, and structured prompts have a far greater impact on long-term stability than simply upgrading to a newer model version.
Despite differences in industries and use cases, a common pattern is evident across all experts interviewed: successful AI teams treat evaluation as an ongoing operational process rather than a once-off testing exercise. To move beyond static validation, organizations must implement systemic guardrails that monitor, catch, and fix errors in real time.
A Practical AI Validation Framework
Transitioning AI systems from static testing to real-time requires a structured, step-by-step blueprint that acts as a protective layer around the model. Here is a practical example of what this looks like:
Step 1: Define Production Risk Categories
Establish clear boundaries to determine how much autonomy the AI has based on each error and risk category:
- Low-Risk: Internal documentation summaries or basic formatting tasks that do not require human auditing.
- Medium-Risk: Customer-facing materials that require automated or human spot-checks.
- High-Risk: Financial calculations, medical estimates and legal compliance text that require mandatory human sign-off.
Step 2: Establish Human Review Thresholds
Determine when human review is needed, and establish strict escalation boundaries. For example, to resolve complex customer complaints, interpret ambiguous photos, or process high-stakes transactions.
Step 3: Monitor Data Drift Continuously
Track live data drift issues by monitoring the system to look for specific signals, including:
- Real-world user queries moving away from the data the model was originally trained on.
- Instances where a model becomes less certain of its own answers.
- A sudden increase in how often the model triggers an automated safety breaker (a system monitor that cuts off the AI when things go wrong).
Step 4: Audit AI Outputs Weekly
To catch hallucinations, bias, inaccuracies and plausible lies, weekly reviews should take randomized samples of both fully automated and human-approved outputs.
Step 5: Create Escalation and Rollback Workflows
Set up clear, automatic steps for teams to take the moment system quality drops:
- Route to Human: Immediately route queries to an expert human team.
- Version Rollback: Revert prompt templates or model versions to the last known stable state.
- Throttling: Safely reduce automation levels until a root-cause analysis can be completed.
By embedding these automated checks and balances into daily operations, organizations can turn AI models from unpredictable risks into controlled, reliable assets.
The Future of the AI Evaluation Framework
As enterprise AI matures, the industry is moving away from static AI evaluation frameworks and towards continuous validation. Going forward, the most successful organizations will be those that build strong hybrid human and AI systems, rather than simply buying the most expensive models.
“The greatest challenge of production performance in AI is calibration of the organization’s trust in those outputs,” explains Tian (GPTZero).
But this trust should always come with clear operational ownership. If organizations blindly trust the outputs, they expose themselves to massive risks, and if they undertrust them, they lose all efficiency.
As Roberts (Esko) highlights:
“Production AI quality is not a one-time model decision. It is an ongoing operating discipline across models, data, prompts, tools, workflows, and human review.”
Benchmark scores should remain useful starting points, however, on their own they are insufficient for measuring true production reliability. Real operational maturity requires a continuous, hybrid system made up of human reviewers, escalation workflows, drift monitoring, and strict governance layers.
By maintaining oversight at every stage of the AI workflow process, enterprise leaders can confidently deploy AI systems that support, protect and enhance their business operations.
About the Author
Stay in the Loop!
Related Content

Ethical Supply Chain: Your Reputation Extends to Your Outsourced Teams
Explore the importance of ethical supply chain management in outsourcing. Learn how BUNCH ensures fair wages, strict working conditions, comprehensive mental health support, and end-to-end compliance to maintain integrity and enhance your brand's reputation.

How AI Spawned "Second-Gen Bias" in Content Moderation Services
AI created a whole new layer of bias nobody saw coming: second-gen bias. Learn how this hidden flaw impacts content moderation and why humans are key to keeping AI in check

How AI Is Changing the Human Side of Customer Support
With AI and automation now part of everyday support structures, the role of humans, and the nature of the work they handle, has evolved dramatically.